Copy-on-Write (CoW) is a data management technique used in computer systems and file systems. It is designed to optimize the way data is copied and modified, particularly in scenarios where multiple processes or users access the same data.
When data is first created or duplicated, CoW doesn’t immediately make a complete copy of it. Instead, it allows multiple users or processes to share the same data, saving both time and storage space. When one of these users needs to modify the shared data, it creates a separate copy of the data only when a modification is requested, ensuring that the original data remains intact. This separation allows the modifying user to work on their private copy without affecting others who are still using the original data. Here, there is a simple diagram illustrating how CoW works:
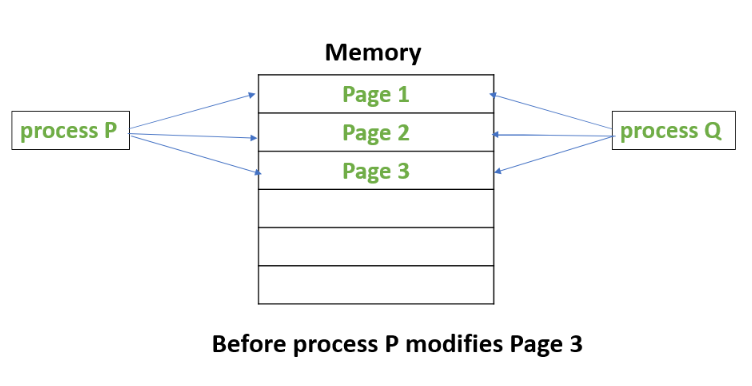
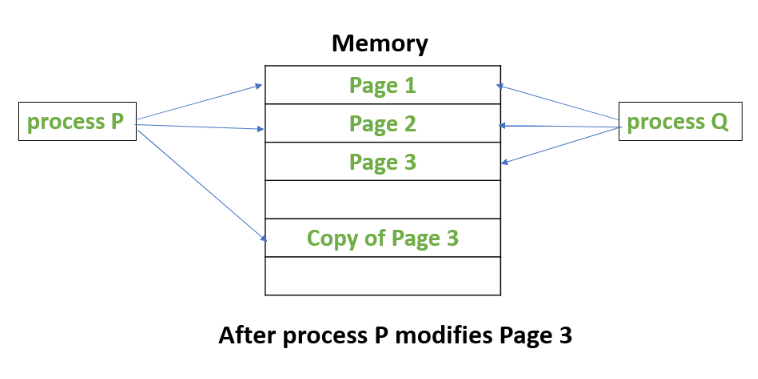
In this example, it demonstrates the use of CoW in virtual memory management. However, CoW is employed in many places, including file systems, as well as within applications and libraries themselves.
For instance, when discussing file systems specifically, Btrfs and ZFS use CoW to maintain the integrity of the file system under unexpected conditions without traditional Journaling. Additionally, this approach provides a valuable feature called “snapshots” which is highly beneficial for data backup, versioning, and recovery purposes.
Additionally, file systems using CoW are a good choice for SSDs because they help prevent unnecessary I/O in file operations. And, in general, thanks to CoW, deduplication (with userspace tools) is quite straightforward, making it possible to save storage space.